Kimi Claw,国内第一批「吃」上 OpenClaw 的 AI。
2026 年,一只小龙虾搅翻了整个 AI 圈,年后 OpenClaw 余热还在继续发力。
近期,多家国内模型厂商先后推出对标 OpenClaw 的产品,Mini Max 推出的 MaxClaw,Kimi 推出的 Kimi Claw,显然,OpenClaw 所展现出的 AI 执行力,以及开发者们对 AI 执行结果所展现出来的包容程度让市场看到了价值空间。
在一众对标产品中,Kimi Claw 的定位比较清晰,它并非从零自研的 Claw 产品,而是基于 OpenClaw 的托管云服务,数据托管在 Moonshot 云端,并且直接配置了 5000+ ClawHub 社区技能。
它的优点在于使用较为稳定,部署方便,上手简单,且依托于云,可以实现 24/7 在线执行运转。打开 Kimi 官网,只需要你一键点击创建,Kimi 就会直接部署 Kimi Claw。
Kimi Claw 一键部署|图片来源:极客公园
换句话来说,Kimi Claw 并也不是一个独立新产品,它本质上就是一台为用户远程开好的虚拟机,让用户通过 Kimi 直接访问运行在云端的 OpenClaw 环境。
它没有做任何功能删减,也没有额外封装,和本地部署 OpenClaw 几乎没有区别,只是把部署、配置、环境搭建这一步替用户完成了,但并没有对 OpenClaw 部署之后的**过程做任何处理。如果没有学会正确给出指令、合理安排任务,其上手难度仍然比较高。
对于从未接触过 OpenClaw 类产品的用户来说,这也会导致一个预期错位,用户以为接入 OpenClaw 就可以做自动化 AI 执行,但其实只是多了一个便携接口,后续仍有很多设置需要自己探索。也因此,为 OpenClaw 类产品提供一些热门的预置 Skills 将会成为不少 AI 模型厂商接下来重点发力的方向。
目前 Kimi Claw 仍处于 Beta 测试阶段,仅对 Kimi Allegretto 以上的会员开放使用权限。
30 分钟搭建自动化办公工作流:
理想很丰满,落地有门槛
我们发现,很多用户和我们一样,接入 OpenClaw 之后,依然摸不清 AI 的执行能力边界,对它到底能做什么、不能做什么充满好奇,但也充满未知,不知道接入之后该从哪里下手。
其实,目前不管是本地部署 OpenClaw 这类自动化 AI,还是直接接入 Kimi Claw 这样的外接入口,整体的使用思路其实可以分成从 0 开始搭建应用和从 0.5 开始优化应用两条路径,我们分别从这两种方式做了实际体验,首先选择从 0 开始开发一个应用,优化工作流。
在体验 Kimi Claw 之前,我先审视了自己有哪些工作可以被打造成一个固定的工作流,或者我的工作流中可以有哪些任务在 AI 加持之下变得更好。而在此之前,我所需要考虑的仅是我与哪个类型的 AI 工具交互可以得到更好的结果。
我选择了工作日记环节,结合每天的工作流,工作记录、工作总结、工作反思等环节最后输出一份当日工作报告。找份报告过去都是个人耗时填写,现在我希望可以 AI 自动抓取,再结合对话式交互自动形成表格。
我先将大致思路递给 AI 优化指令,最后从角色定义、技能配置、数据接入、核心工作流、多媒体表格结构、记忆重点、权限与边界等多个层面给出一个非常长的复杂指令,递给 Kimi Claw。
Kimi Claw 很快分析完指令后,和我确认执行细节。比如说,基础信息、飞书权限、数据存储和触发方式。随后我们开始按照指令去飞书平台搭建飞书应用,并且将把 App ID 和 App Secret 发给 Kimi Claw。
其中有个环节需要在飞书内搭建表格的时候,我让 Kimi Claw 直接给我表格的样式,再递给飞书内置的 AI 系统,让飞书自动搭建表格。

Kimi Claw 搭建的应用页面之一|图片来源:极客公园
在经历了找不到协作者、找不应用页面、找不到 ID 等一系列问题,大约半小时后,我成功接收到了来自 Kimi Claw 的第一条消息。
搭建这个 bot 的速度比我预期要更快。遇到问题时,我会把卡在哪一环直接告诉 Kimi Claw,然后在其给出的方案中选择合适的思路去执行,如果给出的方案没有合适的,会继续追问 Kimi Claw 其他解决方法。

Kimi Claw 一键部署至飞书|图片来源:极客公园
搭建工作流时,跨平台能力的重要性也更加凸显。接连开放 12 条飞书权限之后,我最终搭建 AI 应用并未完成理想状态。其中,我希望 AI 通过阅读我与他人的聊天记录,从而梳理出我的工作任务,但几轮尝试后,AI 应用获取的群聊列表仍为空,并表示飞书 AI 应用要求 AI 只能读取自己参与的会话,应用无法读取群聊列表。
整体体验下来,我认为 Kimi Claw 对一些常规工作流平台比如说飞书、钉钉等开发者工具比较熟悉,基本上给出的指令都能够直接找到对应的执行方式,0 基础用户也能够读懂并执行。但这类企业应用会对自身的信息权限比较看重,开放配置条件也较为严格,或许想要 AI 真正融入工作流,不仅看 Kimi Claw 这类开放者的工具,也需要等待更合适与 AI 融合的应用出现。
而且,运转过程中会出现不少 bug,比如,在此过程中,用户与 Kimi Claw 的交互任务、正在运行的 Agent 任务,会被误统计进个人工作安排。学会修改 bug 也成为** AI 的关键一环。
如果选择从 0 主动定制自己想要的应用或者功能,就需要用户想好清晰的操作路径,具备基本的产品思维。要明确信息输入与输出两端接口的开放程度和连通性,同时控制好每次调用与运行的成本。
本次工作流搭建,全程 token 消耗约 15k-25k,按照 Kimi 的计价方式,大约 1 元左右。但每天大概花费 0.53 元,一个月大约在 15.9 元左右。
自动化 AI 新闻助手搭建实测:
「预制」应用上手快,修改难
除了让 AI 定制化打造一个我设想的应用外,我还体验了一些「预制」应用,比如说让 Kimi Claw 自动抓取新闻。
在我们做第一轮自动化新闻抓取任务时,尝试让 Kimi Claw 抓取某科技新闻媒体官网。当我们给出指令为:
请监控 xxxx 的行业网站,总结最近一周以及未来 3 天内,每当有包含「AI」关键词的新文章发布时,请自动抓取标题、摘要、发布时间,并将这些内容汇总到一个在线表格。同时,请在报告中按照我设定的风格进行爆款文章分析。
Kimi Claw 会询问我们具体配置信息,但第一轮新闻抓取任务时,我们发现不少官网其实都有反爬虫设置,很难去做优质网站的信息监控。Kimi Claw 也很难给出准确的范围抓取,因此会出现空转的情况,而每一次空转都意味着出现大量的 tokens 被消耗。
该监控任务从今天凌晨 4 点到 11 点共运行约 8 次,消耗约 180K tokens,花费约 3.68 元。如果按原设置每小时运行一次,每天成本约 11 元,每月将花费接近 330 元。
随后,我们请教了相关人士后,开始放弃自己写指令,转而从相关 ClawHub 等网站下一个相关指令压缩包,基于此基础指令后,继续定制相关新闻。
将 Clawhub 的文件部署至 Kimi Claw|图片来源:极客公园
随后,我们对中文媒体、新闻筛选条件以及信息发送次数、时间均做了较为详细的设定。最后能够获得一版不错的 AI 新闻抓取结果。
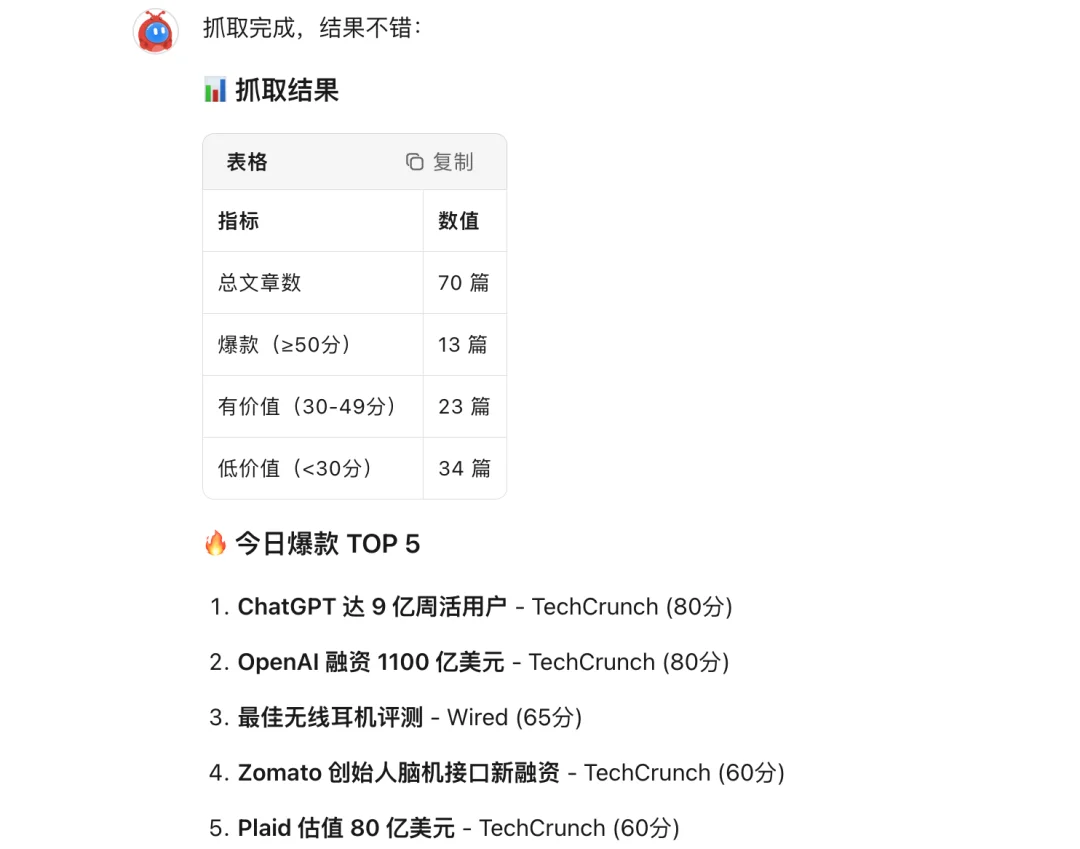
Kimi Claw 自动抓取结果|图片来源:极客公园
很显然,如果只是被动使用预制好的应用,重点则是学会筛选优质的技能包(skills),并且能根据自身场景,对现成功能做适配调优。
但如果想对这些预制好的 AI 应用做定制化修改,往往又会绕回从零搭建应用时遇到的那些难题,开发优化的难度不低,最终改出来的效果也未必理想。
这个过程里,使用者其实需要花大量时间,去体验同一类产品里不同 Skills 的便捷度、适配性,再决定到底基于哪一类 Skills 去做二次开发、修改和扩展。这些其实也考量用户的产品思维。
Kimi Claw 使用观感:
AI 执行力加强,指令就是生产力
现在的现阶段 Kimi Claw 的核心价值,只是降低 OpenClaw 的部署门槛,让国内用户能快速接入。但产品本身不自带场景、不自带技能,更像是一个「转接口」,而非「成品」。
我们在体验过程中同样发现,尽管 Kimi Claw 底层调用的虽然也是 Kimi K2.5 模型,但它是「裸模型+原生 OpenClaw」的组合,没有继承 Kimi 官网版经过搜索团队深度优化的多轮搜索、内容强化、自动纠错等能力。
换句话说,官网 Kimi 好用,是因为背后有专门团队对模型在用户高频场景上做了大量优化、自动补全能力;而 OpenClaw 环境里接入的「裸」模型,更接近直接调用 API,没有进行专门优化,所以会出现同样的指令,递给 Kimi Claw 呈现的效果不如直接递给 Kimi K2.5 模型。
深度体验后我能明显感知,Kimi Claw 和传统 AI、普通 Agent 产品的核心差异,集中体现在 AI 执行力与指令重要性两大维度,这也是使用这类产品的关键逻辑。
首先在执行力上,Kimi Claw 能在你不使用电脑时,同样能够执行任务,而非传统用户给出指令,然后一直等待任务完成的模式。我甚至可以告诉 Kimi Claw 这个指令在什么时候执行,等我开机时能直接看到每一次定时输出的结果。但同时也提醒我,对一些体验性的应用记得设立停止终点,减少不必要的资源消耗。
其次在指令上,过去我与 AI 的指令都会比较简洁、直击问题,当 AI 给出的解决方向不对时,再继续调整。但 Kimi Claw 每一次运行复杂指令的时候,都会调用大量 Agent 协助,消耗的 tokens 也会成倍上涨,因此在给出指令时需要明确操作方式,权限范围、执行路径以及安全性和成本控制。
比如说,过去我查询新闻时的指令时「给出 10 条有关 OpenClaw 的新闻线索,并告诉我其新闻关注价值」,现在我给出的指令则是:
作为信息检索专员,你拥有使用网络搜索工具的权限(限用 web_search 和 web_open_url,禁止访问需登录的付费新闻库),但需在以下约束内执行:
1) 先执行关键词"OpenClaw 最新动态"搜索,仅获取前 5 条高权重结果(优先技术媒体和官方博客,排除论坛水帖);
2) 分析每条的新闻价值时,严格限定在"技术突破"、"商业影响"、"安全隐患"三个维度,每个维度用一句话概括,禁止展开论述无关背景;
3) 全程禁用浏览器自动化点击和深度爬虫技能,避免触发反爬机制和额外 token 消耗;
4) 输出格式为表格:新闻标题 | 来源 | 关注价值标签 | 简要依据(≤30 字/条);
5) 若搜索结果不足 10 条,立即停止补充搜索,直接按实际数量输出,禁止为了凑数发起二次 broad search。预计 token 预算控制在 8K 以内,发现路径偏离时立即终止并汇报而非自行修正。
多数情况下,我甚至会让 AI 优化一下我的指令表达,然后再递给 Kimi Claw。只有给出具体、准确的指令,才能在合理的 token 消耗范围内获得最佳成果。甚至,不少公开论坛上,专门为 OpenClaw 准备的 Skills 库也能够帮助用户更好地上手一些热门应用玩法。
精准、具象的指令,是在合理 token 消耗内获得优质结果的前提,使用 Kimi Claw 的过程,本质就是用户在模型能力、输出结果、使用成本之间做权衡的过程。
Kimi Claw |图片来源:极客公园
最后是,** AI。
即便你快速搭建好的一个 AI 应用之后,你会发现这个 AI bot 并不会一开始就好用。它对于诸多指令的划分,任务的合并其实与人类的理解会有比较大的差异,你仍然需要一轮又一轮的指令**去探索产品的边界。尤其是,很多信息源的接口并不完全对外公开。这其中,想要真正做好信息权的接入和让渡都不是一件易事。
说到底,目前 Kimi Claw 展现出来的应用效果,绝不是一个简单的 Chatbot 之类的 AI 应用,拥有许多 AI 功能供用户直接使用,而是一个需要用户理解开发过程,并且能够在诸多综合权衡后做出选择的开发者工具。只不过这个开发者工具能够支持一些简单化的自动化部署。
自动化 AI 依然有发展空间
尽管 OpenClaw 从 2026 年开始彻底点燃了人们对自动化 AI 的想象,但从近期频发的安全事件与新产品实测体验来看,OpenClaw 至今仍只是一把钥匙、一个契机,而非最终答案。
无论是可落地的真实场景,还是可规模化的商业化路径,AI 行业至今仍未走出一条清晰、成熟的路线。与之相对的是,市场在一轮又一轮的热度炒作中不断抬高对 Claw 类产品预期,甚至吸引了大量普通用户去尝试超出自身能力的高风险操作。
可以确定的是,自动化 AI 从 AI 诞生第一天起就被行业重视,但 OpenClaw 以及 Kimi Claw,能否跑出真正成功、可规模化的产品,依然存在巨大的待验证空间。尤其是现在这类 AI 工具会直接拿到修改你终端、文件的权限。
在早期大家对 AI 的能力边界还不清晰,很多新手小白直接把权限放开,很难想到做安全限制以及二次权限确认。把这么高的操作权交给 AI,本质上也是系统风险直接开口。这也是为什么,这类产品想真正规模化、商业化,安全和权限治理,会是比「能力强不强」更难迈过去的坎。
从直接与大模型对话,到与单一 Agent 交互,再到与 Agent 集群协作,再到如今 OpenClaw 的使用方式,行业在同一段 AI 能力基础上,衍生出了大量功能相似、路径不同的尝试。这恰恰说明,整个行业仍处在 AI 功能探索期,除了 ChatGPT 这类成熟稳定的交互范式之外,人们对于 Agent、Claw 等新形态的使用逻辑、边界与价值,仍在集体摸索。
或许,要等到 2026 年走完,我们才能真正看到一批稳定、可用、具备真实价值的自动化 AI 应用落地。
文章来自于微信公众号 "极客公园",作者 "极客公园"




